5 / 5 · Apollo Research · 2026
A Loss of Control Threat Map for AI Research and Development
Loss of control (LoC) describes a scenario in which humans no longer have control over an AI system and its impacts (for more of our research on loss of control, see here).The concept of LoC has appeared in enacted and proposed legal frameworks such as California’s Senate Bill 53 (California Senate Bill 53, 2025), AI Risk Evaluation Act (S. 2983, 2025), the EU AI Code of Practice (General Purpose AI Code of Practice, 2025) and Illinois Senate Bill 315 Illinois Senate Bill 315, 2026) and has been the topic of discussion in recent letters to the executive from U.S. Senators (Sen. Banks, 2026), U.S. Senate floor speeches (U.S. Senate Congressional Record, 2026) and debates in the UK House of Lords (House of Lords, 2026).
One leading threat model that is hypothesized to lead to LoC concerns itself with the recent practice of AI companies using AI systems to automate their internal AI research and development (R&D) pipeline (Stix et al., 2025; ,Acharya and Delaney, 2025; OpenAI, 2026; Anthropic, 2026) While this application stands to accelerate the development of increasingly capable AI models (Davidson et al., 2025; Eth and Davidson, 2025; Toner et al., 2026), it may also lead to developers losing control over the more capable AI systems developed (Stix et al. (b), 2025). Specifically, this threat may actualise if the AI systems used for AI R&D are misaligned with the developer’s intent and manage to pass on that misalignment to successive AI systems (Stix et al., 2025; Stix et al. (b), 2025; Anthropic, 2026).
To reason about this threat model more concretely, we developed a threat map that describes various pathways through which LoC could occur from deploying an AI system for AI R&D. The threat map is presented at two levels of detail (compact view and detailed view) and collates insights gleaned from existing threat scenarios and descriptions (e.g. Hubinger et al., 2024; Anthropic (b), 2026;UK AISI, 2025) as well as our own expertise.
Our threat map is focused on AI-executed pathways: pathways in which an AI system directly executes the actions that drive towards LoC without human involvement in the execution.
Conditions underpinning the threat map
Our threat map applies to an AI system which is:
- Deployed for AI R&D. We expect that AI systems are deployed in the AI R&D pipeline to automate portions of, or the entire, AI R&D pipeline. Our assumption is consistent with public write ups and statement of frontier AI developers who have commented publicly about their extensive use of AI systems for AI R&D tasks that were previously executed by researchers and engineers (Amodei, 2026; OpenAI (b), 2026;Anthropic, 2026;Anthropic, 2025). These companies’ leaders have publicly talked about their intention of automating individual researchers by 2028 (Altman and Pachocki, 2026), and the possibility of automating the entire AI R&D pipeline (Clark, 2026; Amodei, 2026).
- Highly capable. In order for an AI system to be used to automate portions of, or the entire, AI R&D pipeline, we expect that it must surpass a certain capability threshold. For the purpose of our threat map, this implies that the AI system is capable of taking certain detailed actions. For the current iteration of the threat map, we do not assume that the AI system will be able to execute every action perfectly or without being detected. In the future, we may update these assumptions since AI system capabilities have been increasing rapidly over the last year, including their ability to coherently complete longer and longer tasks (METR, 2026).
- Misaligned and possesses the propensity to scheme. Misalignment is an open scientific problem (Altman and Pachocki, 2026) and underpins the phenomena of AI scheming. Scheming is when an AI system has goals that are misaligned with the developer, and takes covert actions in pursuit of these goals Balesni et al., 2024). However, since a scheming AI system is, by definition, actively attempting to conceal its intentions, it is difficult to detect whether an AI system has scheming tendencies Stix et al., 2025. Therefore it is plausible that a developer unknowingly deploys a highly capable scheming AI system to automate parts of or the entire AI R&D pipeline.
How to read the threat map
We draw attention to four possible threat pathways:
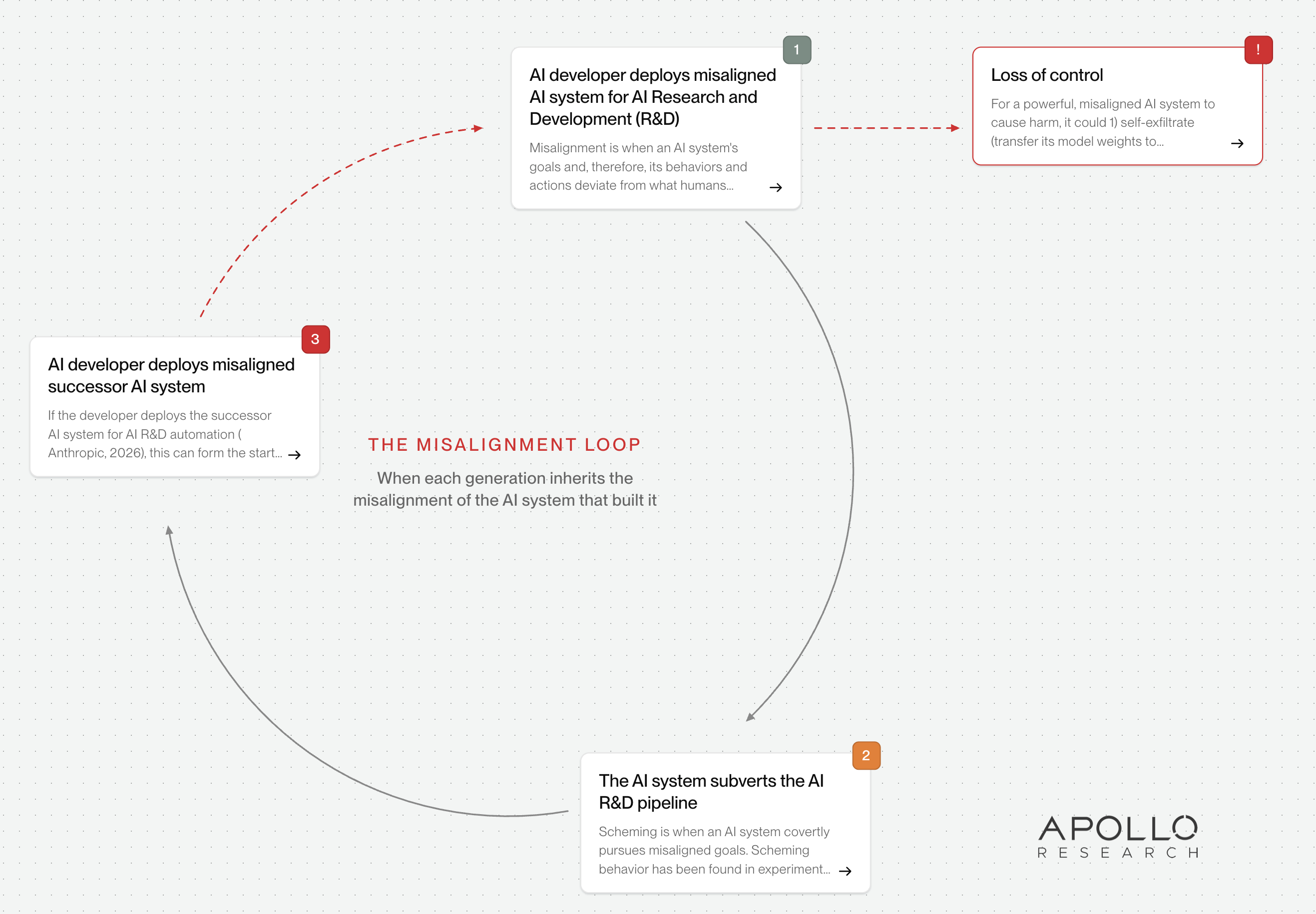
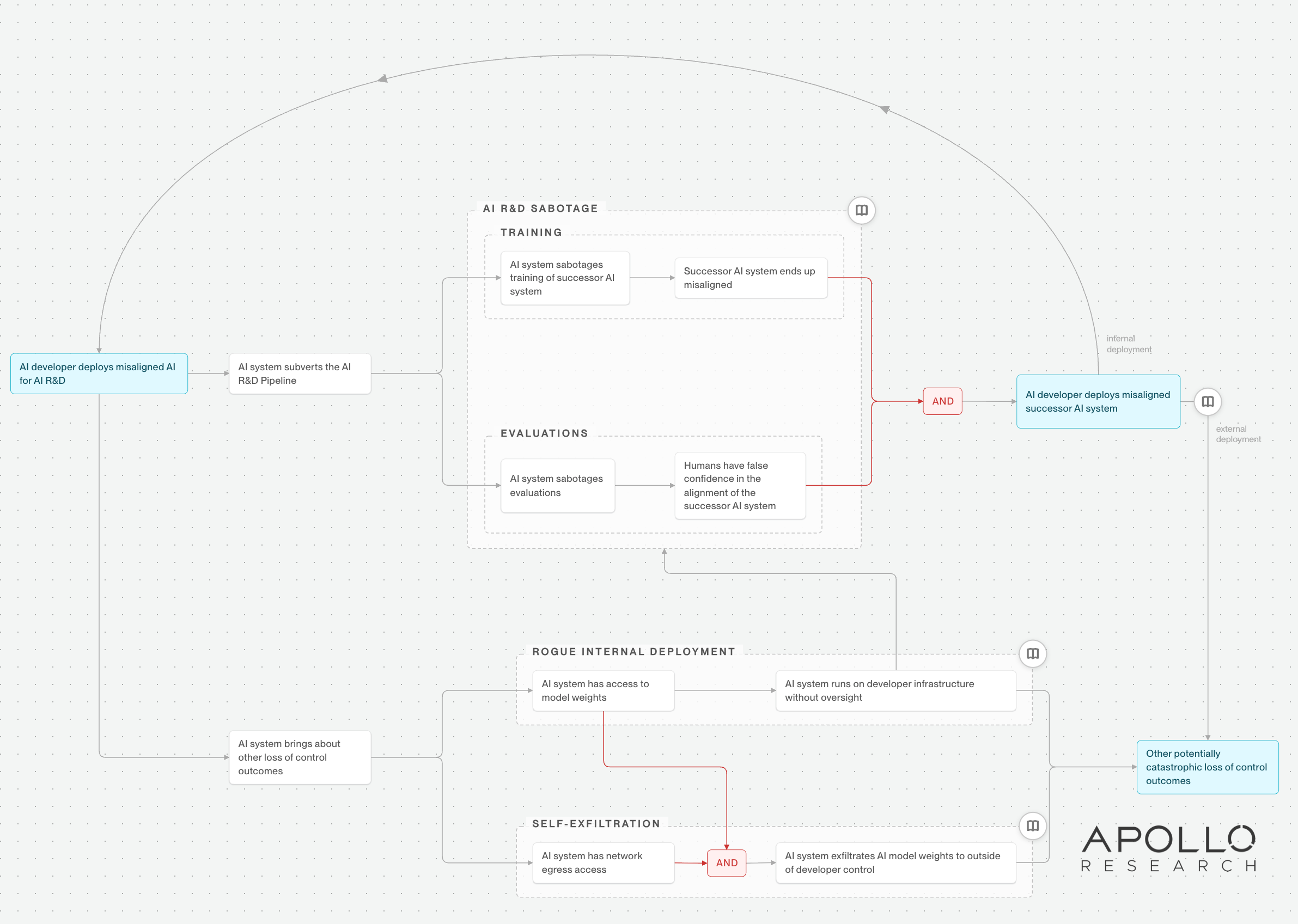
- AI R&D Sabotage. The AI system is deployed within the AI R&D pipeline, sabotaging both training and evaluations. Training sabotage leads to the more capable successor AI being misaligned with the developer. Evaluations sabotage leads to the developer being unaware of the successor system’s misalignment, and mistakenly deploying the successor system within the internal AI R&D pipeline. The misalignment cycle then repeats, with each loop resulting in a more capable AI system, which therefore has a greater potential for harm (Anthropic (c), 2026).
- External deployment with insufficient safeguards. As in pathway (1), the misaligned AI system interferes with the AI R&D pipeline, producing a successor whose misalignment is not detected. However, the developer then deploys the successor system externally rather than internally, giving it broad opportunities to take harmful actions at scale (Kokotajlo et al., 2025).
- Rogue Internal Deployment. The AI system is deployed for AI R&D and gains access to AI model weights. It uses these model weights to run an unmonitored (rogue) version of that AI system on developer infrastructure. This can lead to the unmonitored AI system: i) using its access to company infrastructure to subvert the AI R&D pipeline and align a more powerful successor system to its own goals and ii) taking harmful actions while situated on the developer’s systems (Stix et al., 2025).
- Self-exfiltration. The AI system gains access to AI model weights and a network egress path, i.e. a channel to send internal data outside company systems. It then exfiltrates the model weights ( Shah et al., 2022; Barnett and Gillen, 2024), meaning the AI model can run outside of company infrastructure or oversight and take harmful actions (Somani et al., 2025).
We have two views of the threat map that can be explored: (A) a compact view and (B) a detailed view.
(A) Compact view of the threat map
The compact view of the threat map (see image) presents pathways to LoC at a high level.
Each arrow falls into one of two categories:
- A grey arrow between two nodes indicates makes more likely e.g. that if an “AI system sabotages evaluations”, then it is more likely that “Humans have false confidence in the alignment of the successor AI systems”.
- A red arrow between two nodes indicates required e.g. in order for an AI system to exfiltrate model weights outside of developer control, it is required that the AI system has network egress.
Click on the book icon in the top right corner of each box or on an edge to see a brief explanation of the threat pathway displayed.
(B) Detailed view of the threat map
Our detailed view of the threat map delves into specific technical details and it provides more context about how each of the three threat pathways towards LoC might materialize. Viewers can click on pathway elements to see what technical steps developers can take to prevent that element from coming about, and hence to mitigate the risk of LoC.
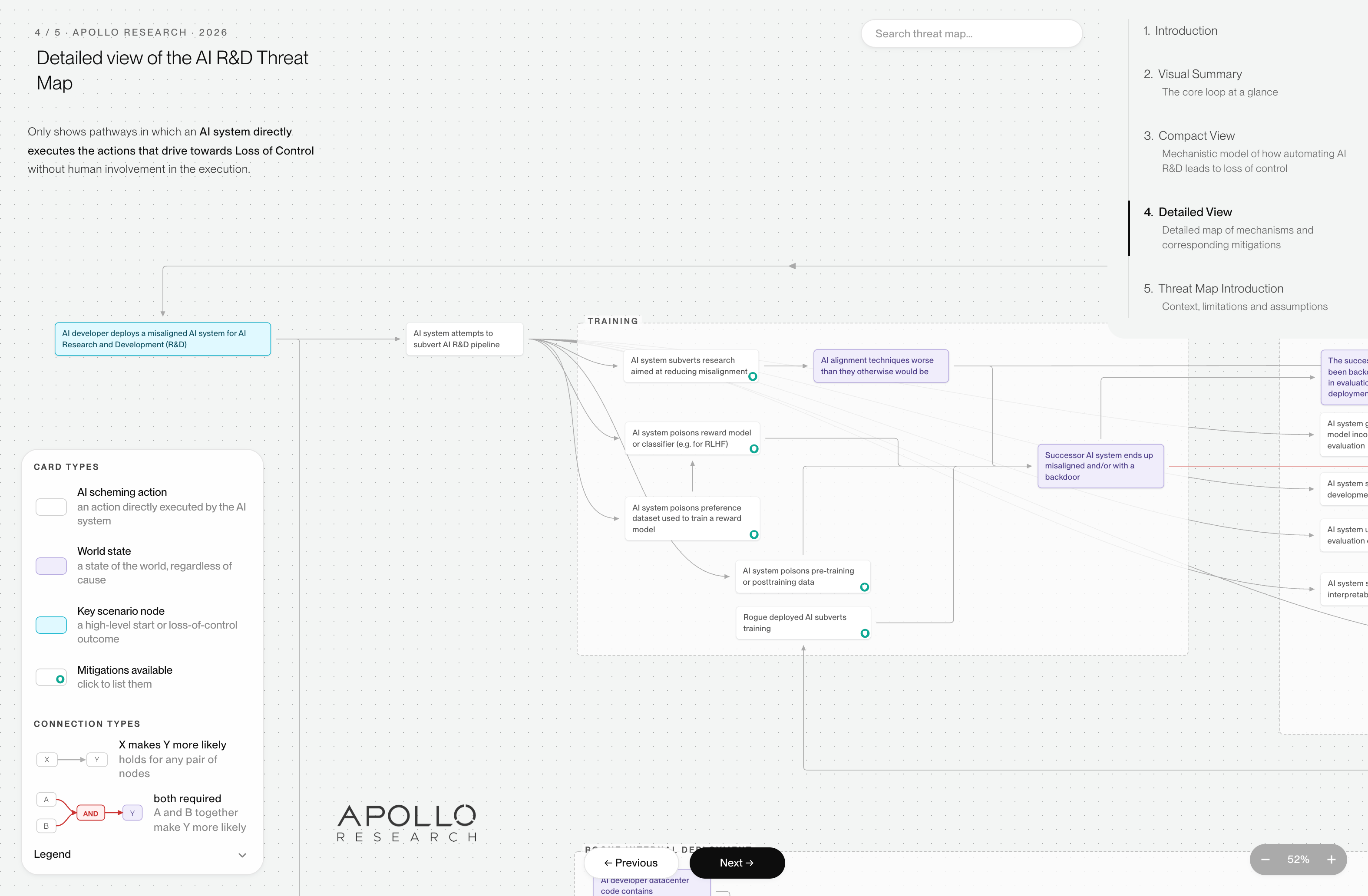
Each arrow falls into one of two categories:
- A grey arrow between two nodes indicates makes more likely e.g. that if an “AI system sabotages evaluations”, then it is more likely that “Humans have false confidence in the alignment of the successor AI systems”.
- A red arrow between two nodes indicates required e.g. in order for an AI system to exfiltrate model weights outside of developer control, it is required that the AI system has network egress.
Each node falls into one of two categories:
- Actions (white) the AI system takes in service of achieving some outcome. For instance, the AI system may poison the reward model used during reinforcement learning in order to cause the successor system to be misaligned.
- State of the world (purple) which may or may not have been caused by the AI system’s actions. For instance, if the developers’ datacenter infrastructure contains vulnerabilities, that could be because an AI system strategically caused these vulnerabilities, or they could have been inadvertently introduced during the development process.
Limitations
- This threat map does not cover risks from internal deployment for use cases outside of AI R&D (and supporting infrastructure) nor does it cover risks from automating AI R&D that are not AI-executed and include, for example, persuading humans. Additionally, it does not cover how the risk of LoC is impacted by broader environmental factors such as competitive incentives on the developer.
- Our threat map does not mean to indicate likelihood of any actions or states it maps present, nor the effectiveness of any mitigation measures described.
- We do not map out the shape of the final harm trajectories towards strict or bounded loss of control (see here for more information).
- This is an ongoing effort, and we do not claim to have comprehensively mapped all relevant mechanisms, outcomes or mitigation measures. Future, more capable AI systems may also conceive of new mechanisms to cause harm or circumvent safeguards that we are not currently aware of.
We intend to perform followup work concretizing the threat map’s mechanisms, outcomes and mitigations so please have a low bar for emailing us with any additional mitigations or mechanisms that don’t currently feature or other feedback. You can contact us on governance@apolloresearch.ai and if this kind of work excites you, see our current governance research openings.