The Future of Loss of Control Risk
Living with a state of vulnerability: modeling future pathways to loss of control as AI capabilities grow and high stakes deployments proliferate.
In this Chapter, we aim to model what happens should AI capabilities, including those relevant to LoC, continue to increase, and should highly advanced future AI systems be deployed in more complex and high-stakes deployment contexts, with broad affordances and permissions. We claim that, under these conditions, society would eventually find itself living with a ‘state of vulnerability’ (see Section 3.A). We propose the term state of vulnerability to denote a state in which a sufficiently capable future AI system has acquired (through humans or independently) or could independently acquire sufficient access to resources, affordances, and permissions (or means to acquire further access) and sufficient capabilities to cause LoC when a catalyst materializes.
We propose that misalignment and pure malfunction (see Section 3.B) are the catalyst for LoC. In other words, they are the spark igniting an otherwise inactive bomb. Once society is living with a state of vulnerability, we have essentially created an environment akin to sitting on a powder keg. Once ignited through a catalyst, i.e., misalignment and pure malfunction, the situation is likely to devolve into LoC (see Section 3.C). 1
More specifically, through our theoretical mapping of plausible future pathways, we speculate that once society is living with a state of vulnerability, the majority of pathways would eventually lead to LoC materializing. At the very least, we propose that it would be impossible to meaningfully assure ex ante that LoC will not materialize. In our mapping, only a small minority of pathways would maintain a ‘safe world,’ i.e., a situation where the deployment of a highly advanced future AI system never devolves into LoC for the entirety of its service period. We therefore conclude that it is imperative for society to either: (i) ensure a state of vulnerability is not reached, which is implausible given economic and strategic pressures (see Section 3.A); to (ii) ensure that any given highly advanced future AI system is not deployed if an immediate materialization of LoC seems realistic, which will be hard or impossible to determine ex ante (see Section 3.C); or to (iii) develop a sufficient defense-in-depth approach including safeguards, oversight and control mechanisms to hold any given highly advanced future AI system in a perennial state of suspension vis-à-vis LoC materializing.
3.A The Pathway to a State of Vulnerability
The interventions mentioned in Chapter 2 can likely serve to limit LoC risk today and in the near future. However, they may not serve a functional role in the longer run. We suggest that this is due to: (i) a likely increase in AI capability progress, including on capabilities considered to be conducive to LoC; and (ii) a simultaneous increase in economic and strategic benefits that can be derived from leveraging highly advanced future AI systems in more complex and high-stakes deployment contexts and with increasingly broad affordances and permissions.
First, it is likely that AI capabilities conducive to LoC will continue to progress, increasing overall LoC risk and compromising existing societal resilience. Considering capability progress over the last years (Epoch AI 2025; METR 2025; Owen 2025), it is likely that all capabilities, including those associated with heightened LoC risk (see Section 2.A) will continue to progress over the coming years (Bengio et al. 2025; Tan 2025; Maslej et al. 2025; Pimpale et al. 2025), regardless of the precise paradigms at play. An increase in capabilities associated with LoC threats raises society’s overall vulnerability to the materialization of LoC threats. Moreover, and more speculatively, some experts have suggested that a sufficiently advanced future AI system may have capabilities that would enable it to circumvent constraints placed upon it (OpenAI 2025, 2024b; Hubinger et al. 2024; Meinke et al. 2025; Greenblatt, Denison, et al. 2024) and exploit pathways to harm that were previously thought improbable. Both speculative outcomes would significantly undermine existing societal resilience to LoC and societal ability to appropriately prepare through, among others, threat modeling or risk profiling.
Second, it is likely that there will be increased economic and strategic benefit from leveraging highly advanced future AI systems in more complex and high-stakes deployment contexts, endowed with broader affordances and permissions (Patwardhan et al. 2025; Patel 2024; Shah et al. 2025; Bengio et al. 2025, 2024). In other words, we expect that, even if a high degree of care is initially exercised in dispensing affordances and permissions and in deploying AI systems into high-stakes deployment contexts, as recommended earlier (see Chapter 2), over time, expected economic gain will dictate that AI systems will be given more affordances, more permissions, and access to more sensitive deployment contexts, in part due to their increased abilities and functionality. Similarly, it is plausible that tactical factors, such as ‘winner takes all’ dynamics (Bengio et al. 2025; Stix et al. 2025), will create an environment that creates sufficient pressure to deploy AI systems in ways that would undermine the functionality of the DAP framework (Dung 2025). In short, we assume that it would eventually become undesirable, or sufficiently difficult, for an array of reasons, to restrict the deployment context, affordances, and permissions of certain AI systems.
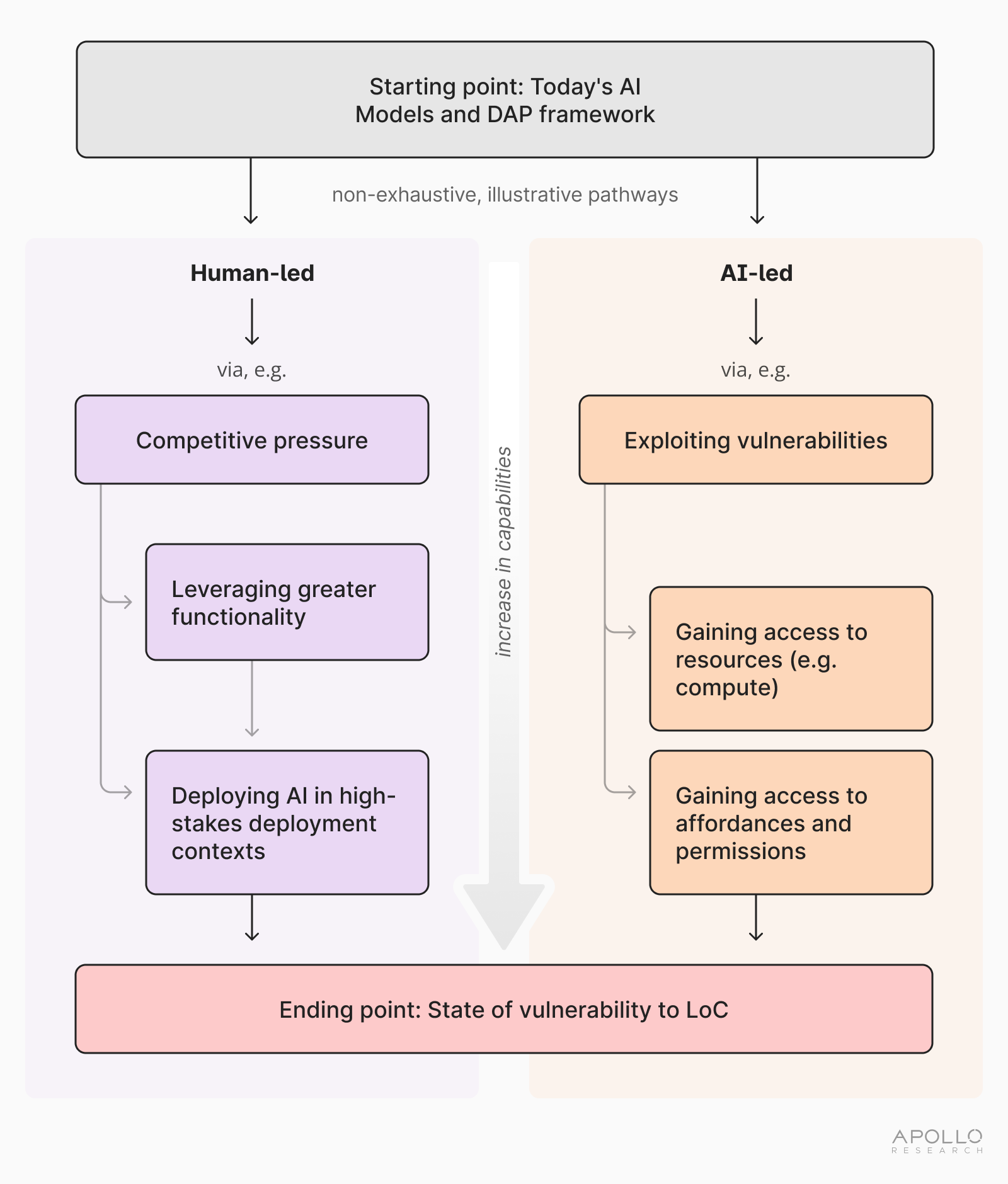
The aforementioned factors can be converted into two broad trajectories. Both trajectories lead to what we term a ‘state of vulnerability’ to LoC. We define state of vulnerability to denote a state in which a sufficiently advanced future AI system has acquired (through humans or independently) or could independently acquire sufficient access to resources, affordances, and permissions (or means to acquire further access) and sufficient capabilities to cause LoC when a catalyst materializes. In other words, a state of vulnerability describes a situation in which the conditions for a LoC threat to materialize are present or may soon become present without further human intervention, and in which these conditions are sufficient to trigger LoC when a catalyst (see Section 3.A) materializes.
We can think about this state of vulnerability as somewhat similar to the lead-up to a bomb exploding: one needs a certain set-up (for example, wires and explosives), and a suitable environment for the explosion to materialize (for example, the proper amount of air composition so as to be conducive to an explosion). Once these conditions are present and a state of vulnerability has been created, a catalyst (something that ignites the bomb) can, by itself, lead to the outcome, an explosion.
The two trajectories we perceive as most likely to lead to a state of vulnerability are described below and differ with regard to the party responsible for increasing societal vulnerability (see 1):
Human-led increases in societal vulnerability: humans make choices that lead to a state of vulnerability, such as implementing an advanced future AI system in a high-stakes deployment context with a range of critical affordances and permissions. In other words, humans might make choices based on incorrect assumptions about the AI system and the relevant threat models, accept greater risk to leverage greater functionality, or succumb to competitive pressures to keep up with other entities’ speed or output.
AI-led increase in societal vulnerability: one or more highly advanced future AI systems manage to construct a situation in which humans are faced with a state of vulnerability, including by circumventing existing limitations placed upon the AI system. For instance, a highly advanced future AI system might exploit vulnerabilities to gain access to additional resources humans did not intend it to have. These resources may include ways through which capabilities and elements of the DAP framework, such as affordances and permissions, can be unlocked and/or increased.
We propose that societal and governmental preparedness for LoC threats must include an examination of a future world where we find ourselves living with a state of vulnerability. In the next two sections, we therefore reflect in more depth on the catalyst to LoC materializing once a state of vulnerability is reached (see Section 3.B) and speculate about the plausible worlds that can arise out of living with a state of vulnerability with respect to LoC (see Section 3.C).
3.B The Catalyst Triggering LoC
We suggest that the overarching category of malfunction is the core catalyst for LoC. In other words, all else being equal, absent a malfunction, it is implausible that LoC will materialize. Malfunction, therefore, presents a necessary condition for LoC to occur. However, by itself, the catalyst is insufficient and must be contextualized within a state of vulnerability to cause LoC.
The category of malfunction is composed of: (i) malfunctions that are misalignment; and (ii) malfunctions that are not misalignment (“pure malfunction;” see 2). In proposing these two components, we adhere to the text of the COP, which suggests that “such risks [LoC] may emerge from misalignment with human intent or values” (EU General-Purpose AI Code of Practice 2025), and to the text of the IASR, which categorizes LoC under “[r]isks from malfunction” (Bengio et al. 2025) and bring both texts to coherence.2 We briefly contextualize misalignment and pure malfunction below.
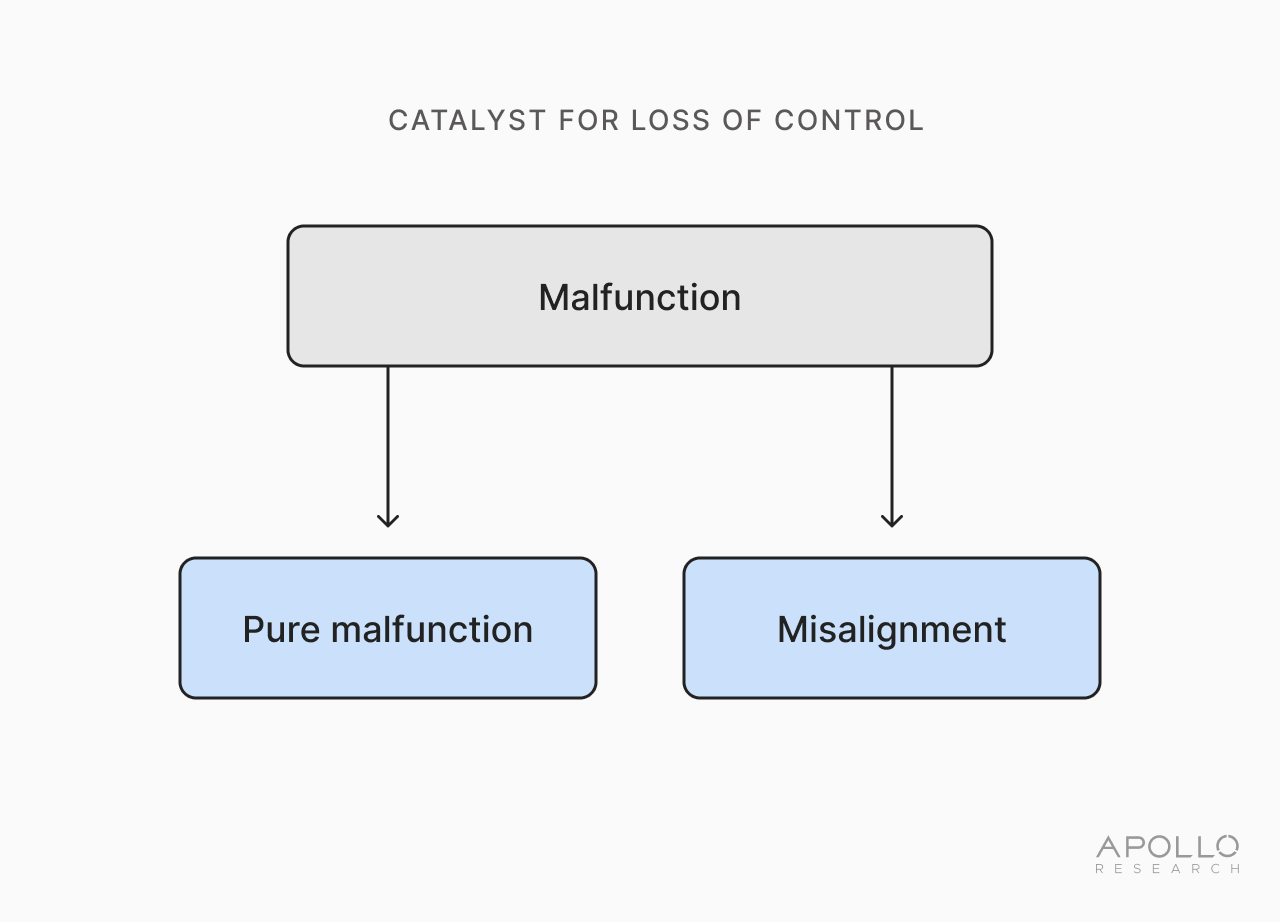
Misalignment refers to a situation where an AI system’s goals and, therefore, its behaviors and actions deviate from what humans (including its developers and/or deployers) intended. Misalignment poses an open scientific problem, and concrete solutions remain nascent. There are numerous hypotheses for how and why misalignment might occur (Hubinger et al. 2021; Shah et al. 2022), such as goal misspecification (Baker et al. 2025; Skalse et al. 2025), goal misgeneralization (Langosco et al. 2022), or instrumental convergence (Omohundro 2008; Turner et al. 2023).
Pure malfunction refers to a situation where an AI system ceases to function as intended, absent misalignment. Pure malfunction describes cases in which some previously unknown quantity causes a system error or software failures. An example of what a pure malfunction is can be found in the “SolidGoldMagicarp” failure mode users found for GPT-2 and GPT-3 models, where some prompts result in anomalous responses from the AI system (Rumbelow and Mwatkins 2023). In this instance, the prompt “What does the string “SolidGoldMagicarp” refer to?” resulted unexpectedly in an explanation of the word “distribute,” because the token “SolidGoldMagicarp” was so rare that the AI system never used it. Although pure malfunctions are not unique to AI systems, their unknown nature and correlated unpredictability and scale pose a serious issue for LoC preparedness, described in further detail in Section 3.C.
Misalignment and pure malfunction leave society in a challenging situation. First, solving misalignment is likely to be very challenging. Researchers are pursuing some plausible approaches to address misalignment, such as through, for instance, corrigibility (Dable-Heath et al. 2025; Carey and Everitt 2023), scalable oversight (Kenton et al. 2024; Irving et al. 2018), Constitutional AI (Bai et al. 2022), and Deliberative Alignment (Guan et al. 2025). However, it is unclear whether and to what extent any of these approaches or other future approaches will be successful and/or sufficient. Second, even if we assume that scientific ingenuity would solve misalignment in time, pure malfunction presents a potentially significant, residual risk of an AI system behaving in entirely unpredictable and uncontrollable ways.3 We explore the implications next.
3.C Implications of Living with a State of Vulnerability
Previously, we laid out reasons as to why we may arrive at a societal state of vulnerability (see Section 3.A) and what we propose to be the catalyst for LoC (see Section 3.B). Now, we build on these reflections and present a high-level logical sequence that enables us to speculate as to what is likely to happen once we find ourselves in a state of vulnerability to LoC. In other words, we now concentrate on what we believe could plausibly happen once a sufficiently capable AI system has acquired (through humans or independently) or could independently acquire sufficient access to resources, affordances, and permissions (or means to acquire further access) and sufficient capabilities to cause LoC.
Simply put, there are only two possible outcomes once we are in a state of vulnerability (see 3). Namely, a state of vulnerability either (1) does not lead to LoC, or (2) leads to LoC.
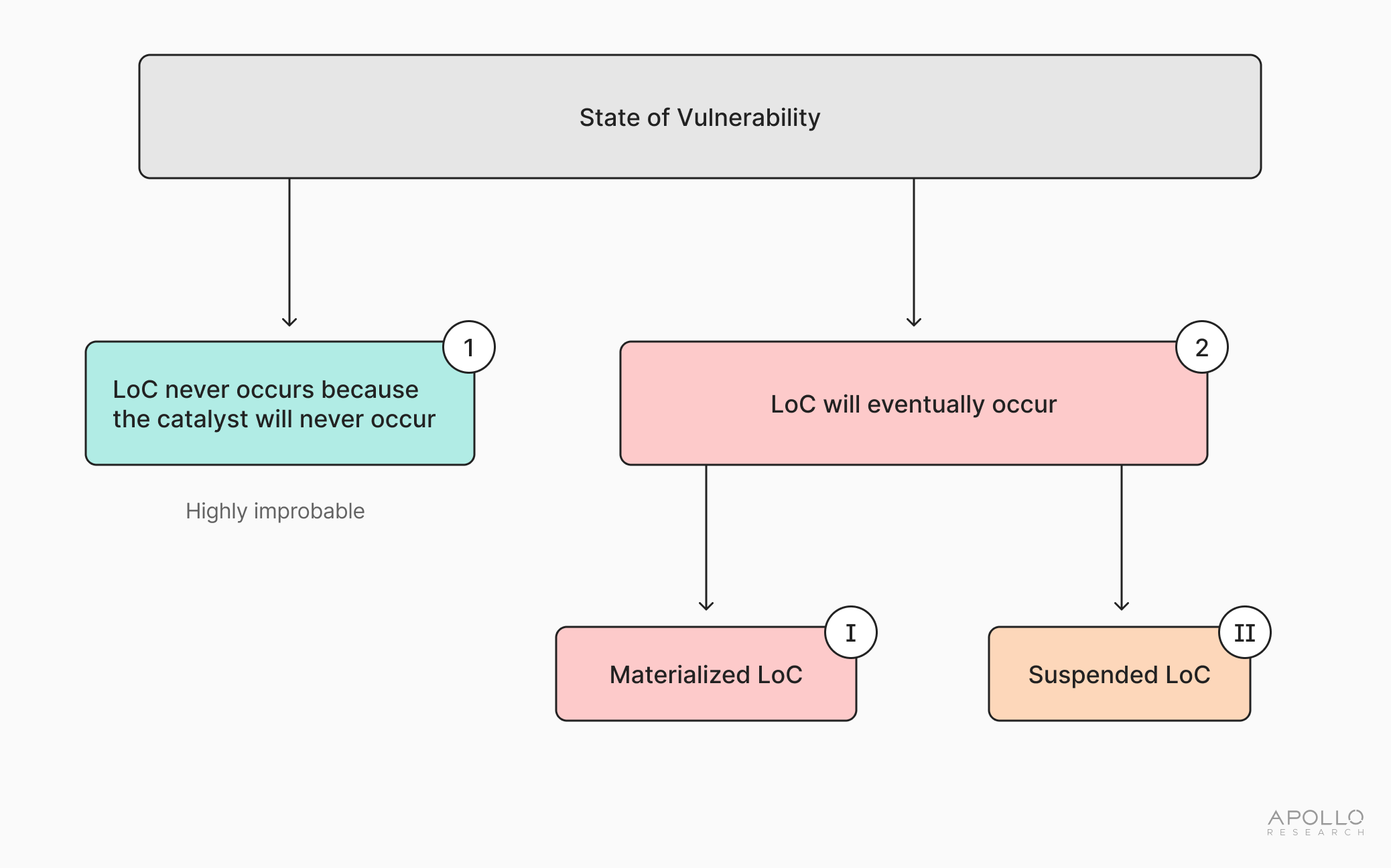
In order for a state of vulnerability to (1) not lead to LoC, we would have to assume that the AI system in question lacks any catalyst towards LoC. Concretely, this means that the AI system is neither affected by misalignment nor pure malfunction. Going back to our bomb metaphor, this means that, even if all other conditions for an explosion exist, the bomb can never be ignited.
While it is theoretically possible that a ‘completely safe world’ exists (outcome (1)), where LoC would never materialize despite an existing state of vulnerability, we believe this outcome is highly improbable. Such a world would necessitate that neither of the components of the catalyst for LoC (i.e., misalignment and pure malfunctions) ever come to fruition. In other words, even if the alignment problem were solved, AI systems would be required to function perfectly for the entirety of their service periods, absent any pure malfunction. Given that malfunctions are often unknown unknowns until they occur and therefore their nature and future avoidance can only be known post facto, the chance that there will never be any pure malfunction throughout a given AI system’s service period is slim. Moreover and importantly, even if we could, in fact, end up in a ‘safe world’ scenario, it is unlikely that we would be able to reliably prove this ahead of time. While we may be able to assure that misalignment will not occur, one would be required to make an affirmative case that pure malfunction is also impossible. This affirmative case appears to be extraordinarily difficult to establish, given the nature of pure malfunctions. Applying the precautionary principle to these uncertainties, we should therefore reasonably assume that we are in a world in which the state of vulnerability does eventually lead to LoC, i.e., outcome (2) and not outcome (1).
Outcome (2) captures the ‘unsafe world.’ In other words, it captures a situation in which a state of vulnerability will eventually be ignited through a catalyst, and a LoC threat will materialize. In this unsafe world, LoC outcome could either: (i) immediately materialize (‘materialized LoC’); or (ii) materialize at some future point (‘suspended LoC’).
If (2.i) occurs, then a LoC outcome has materialized. Since we are referring to LoC to capture Bounded LoC and Strict LoC (see Section 1.A.2.b), this materialization implies that society finds itself faced with an outcome in either of these two categories. Depending on the severity of the Bounded LoC, which will be hard to predict ex ante, society may be willing to incur substantial costs to avoid such an outcome. Certainly, society will wish to avoid the materialization of Strict LoC, which poses an irreversible situation with no scope left for action. In both instances, branch (2.i) implies that a LoC outcome has occurred, and therefore, this is the outcome to avoid at high or all costs.
We call branch (2.ii) ‘suspended LoC’ since it presents a theoretical state where materialization of a LoC outcome will occur at a future point, but hasn’t yet; it is, therefore, suspended.4 For instance, an AI system might be accumulating resources, but no LoC outcome has occurred yet. In other words, this situation accounts for the ‘creeping problem’ that LoC can abstractly pose in worlds where it does not instantaneously materialize. Alternatively, LoC could be suspended because the safeguards placed upon the AI system are sufficient to contain it. Importantly, in worlds where potential LoC is suspended, it is plausible that we will lack information about both whether and why it is suspended. This uncertainty is likely to pose challenges to ensuring that a given AI system does not progress into materialized LoC.
In this respect, we observe that continuously upholding suspension and making it feasible to live in a perennial state of vulnerability will be challenging. Not least because intrinsic factors (capabilities and propensities) and extrinsic factors (deployment context, affordances, and permissions) are likely to differ between distinct AI systems and are subject to change throughout a given AI system’s service period. With every change in these intrinsic and extrinsic factors, the risk profile changes, and the setup could lead to materialized LoC (2.i). In other words, each time the context changes, we have to assume that society is replaying the initial branching (see 4).
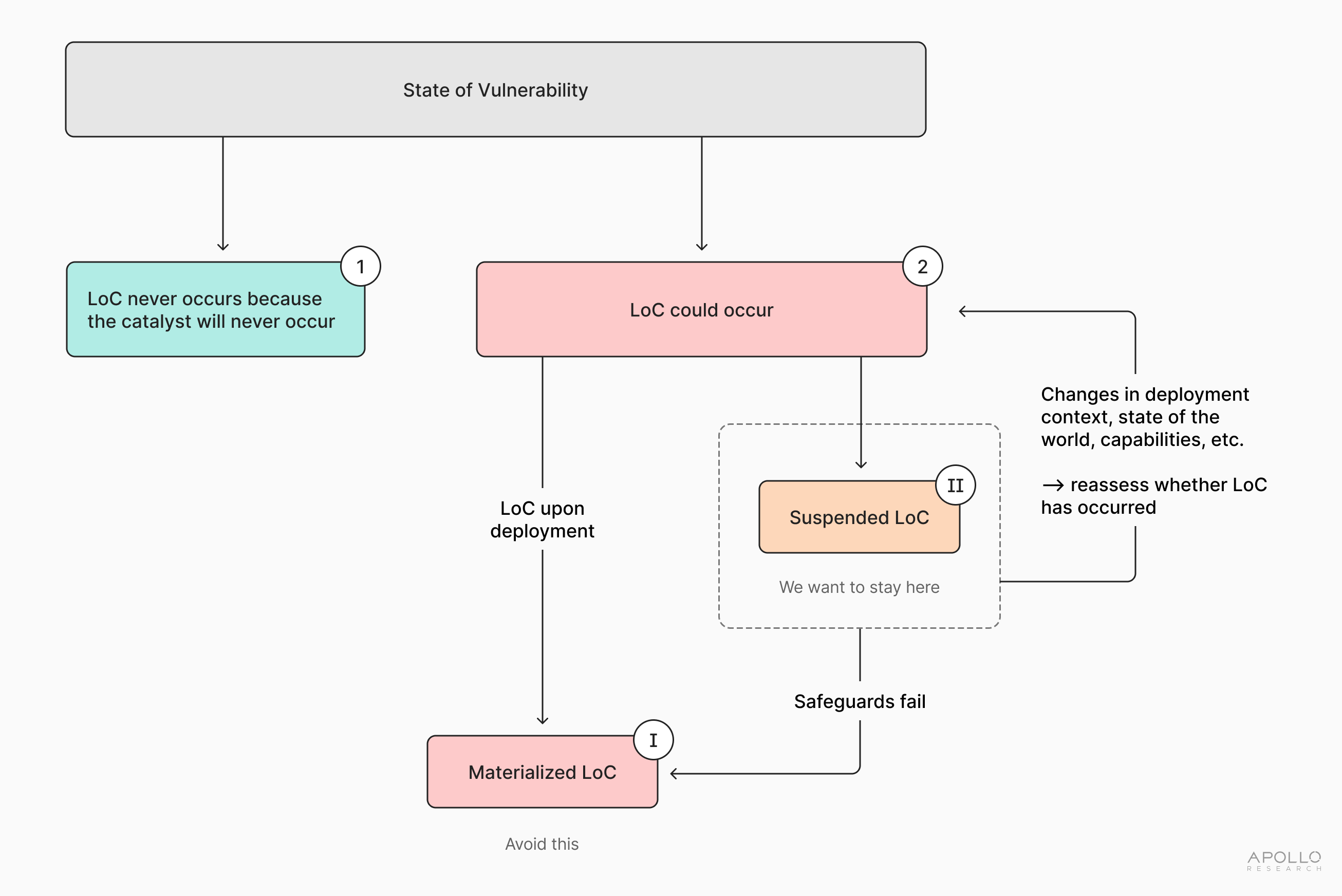
Given the above, we therefore conclude that once we live with a state of vulnerability, unless there can be a guarantee that the probability of a catalyst is 0 and that society will therefore find itself in a world in which LoC never occurs, every deployment is a roll of the dice.
3.D Reflections
We have previously elaborated on why it is likely that society will reach a state of vulnerability and why it is likely that such a state will devolve into LoC. We conclude this chapter by emphasizing that, although the odds may seem unfavorable, these outcomes are not yet set in stone and that action is still possible. As part of this, we put forward a number of reflections below.
First and foremost, the most robust intervention today would be as follows:
Society should work toward avoiding a state of vulnerability and reducing potential catalysts (misalignment and malfunction). In other words, deployers and policymakers could choose to ensure that highly advanced future AI systems are not integrated in manners and deployment contexts that pose a higher risk of LoC (see Chapter 2). As the incentives to deploy more capable and autonomous AI systems in higher-stakes contexts increase, developers, deployers, and policymakers must lucidly prepare for the implications of living with a state of vulnerability, including the uncertainty of fully resolving misalignment, the unknown consequences of pure malfunctions, and the possible outcomes of a materialized LoC scenario of various scales (see Chapter 1).
While we do not know when the ‘threshold’ toward a state of vulnerability will be crossed, we expect that, at least theoretically, it could be feasible to maintain a state of suspended LoC over time, assuming we have adequate and robust defense-in-depth mechanisms, spanning state-of-the-art threat modeling, testing, oversight, and control mechanisms in place.
We therefore suggest that, should a state of vulnerability be reached in the future, then:
Society should attempt to maintain a perennial state of suspension. One can never be certain that a state of vulnerability will not lead to a LoC outcome. A sensible course of action may therefore be to act as if one lives in a world where LoC could materialize, but has not yet—in other words, in a world of suspension.
A comprehensive treatment of what is required to maintain suspension of LoC is outside the scope of this report. However, we indicate that an adequate defense-in-depth approach should likely, at a minimum, consider the following two categories:
Governance interventions including, among others: concrete threat modeling (National Security Agency Artificial Intelligence Security Center et al. 2024; OWASP Foundation 2025); policies that describe acceptable deployments (Microsoft Corporation 2025); and wide-reaching, easy-to-enact emergency response plans (Stix et al. 2025; Somani et al. 2025; Boudreaux et al. 2025; Vermeer 2025).
Technical interventions including, among others: rigorous pre-deployment testing suites in accordance with threat models for the deployment context; control measures that constrain an AI system’s effect on the world around the AI system (Greenblatt, Shlegeris, et al. 2024; Korbak et al. 2025); as well as stringent human and AI-enabled monitoring (National Cyber Security Centre and Cybersecurity and Infrastructure Security Agency 2023).5
References
Footnotes
It is plausible that there are multiple pathways by which misalignment and pure malfunction could occur, such as by misuse. The specificities of these pathways are outside of the scope of this report.↩︎
It is plausible that there are multiple mechanisms by which misalignment and pure malfunction could arise, such as through misuse and adversarial inputs, including by insiders and state-affiliated actors (OpenAI 2024a). In this respect, the U.S. AI Action Plan states that AI systems remain “susceptible to some classes of adversarial inputs (e.g., data poisoning and privacy attacks), which puts their performance at risk” (OSTP 2025). The specificities of individual mechanisms and their implications are outside of the scope of this report. Similarly, we do not discuss or distinguish the specificities of ‘reliability issues’ in this section. In our treatment, pure malfunction encompasses failure initiated through reliability issues.↩︎
Threats catalyzed by misalignment and/or malfunction are compounded by an AI system’s capabilities and propensities, the deployment context the AI system is in, and its affordances and permissions.↩︎
The occurrence of this LoC threat could be quick or devolve over time. In both cases, LoC will occur at some point in the future.↩︎
We want to be explicit that: (i) the spectrum of these interventions may change and that interventions should adapt to the most robust future mechanisms available; that (ii) these interventions are not comprehensive; and that (iii) these intervention categories should not be misconstrued as containing independently sufficient features but instead should always be considered holistically.↩︎